
Llama-2-7B-32K-Instruct Achieves State-of-the-Art Performance


A new AI model called Llama-2-7B-32K-Instruct, developed by Together AI, achieves impressive results on long-context natural language tasks like summarization and question answering. The model was built by fine-tuning Llama-2-7B-32K, an open-source language model, using a dataset of human instructions and conversations.
Fine-tuning was done through Together AI's API in just a few hours. The process involved four main steps: collecting instructional data by querying the powerful Llama-2-70B-Chat model, training the 32K model on this data plus existing summarization and QA datasets, testing in Together's playground, and finally deploying through their inference API.
Evaluations show Llama-2-7B-32K-Instruct reaches state-of-the-art performance on summarization and long-context QA with 50 documents. It matches or exceeds GPT-3.5-Turbo-16K, despite having fewer parameters. For short contexts, it retains capabilities on par with Llama-2-7B-Chat.
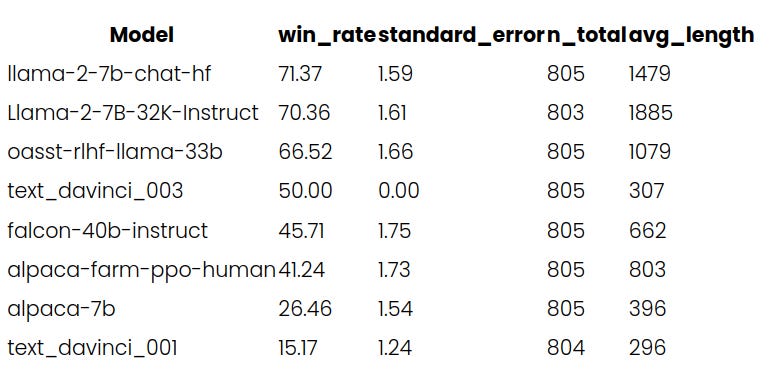
This demonstrates the power of transfer learning - taking an existing model and customizing it for specific tasks with a small dataset. Together API makes this approach highly accessible. The full fine-tuning recipe they used is available on GitHub.
Long-context reasoning has been a challenge for large language models. This development shows the rapid progress that is still being made to expand these models' reasoning and memory capabilities.
Llama-2-7B-32K-Instruct could enable more human-like conversational AI and greatly benefit applications like search, customer support, and document analytics that require deep understanding of long texts. Its state-of-the-art results highlight the potential for customized models to surpass even the most capable generic models.