


The Quest to Overcome Key Challenges in Large Language Models
Large language models (LLMs) have rapidly risen to prominence, demonstrating impressive capabilities on a range of natural language tasks. However, as outlined in a new survey paper, major challenges remain unresolved that could constrain real-world applications.
The paper by Jean Kaddour, Joshua Harris, Robert McHardy and colleagues provides a timely overview of the field, synthesizing key achievements while spotlighting limitations that must be addressed. The authors "aim to establish a systematic set of open problems and application successes so that ML researchers can comprehend the field’s current state more quickly and become productive".
On the achievements front, models like GPT-3 and PaLM have shown they can perform language tasks like translation, question answering, and text generation at superhuman levels in controlled settings. For example, GPT-4 can reportedly achieve human-level performance on certain standardized tests.

However, the authors argue we have not yet laid the proper foundations to ensure these powerful models are steered towards beneficial outcomes. LLMs still face significant challenges around robustness, safety and transparency.
Key problems include the inability to fully comprehend massive training

datasets, high costs to train models, and difficulties ensuring they behave as intended without harm. LLMs can sometimes hallucinate facts or exhibit harmful biases inherited from data.
To address these constraints, the authors recommend more rigorous experimental methods, increased control over training data/procedures, and smarter prompting techniques to improve robustness. Developing solutions in these areas will be critical to unlocking LLMs' immense potential while mitigating risks.
This paper is a must-read for anyone striving to deeply comprehend the field of LLMs. By spotlighting achievements and persisting challenges, it charts a path towards overcoming barriers to real-world application.
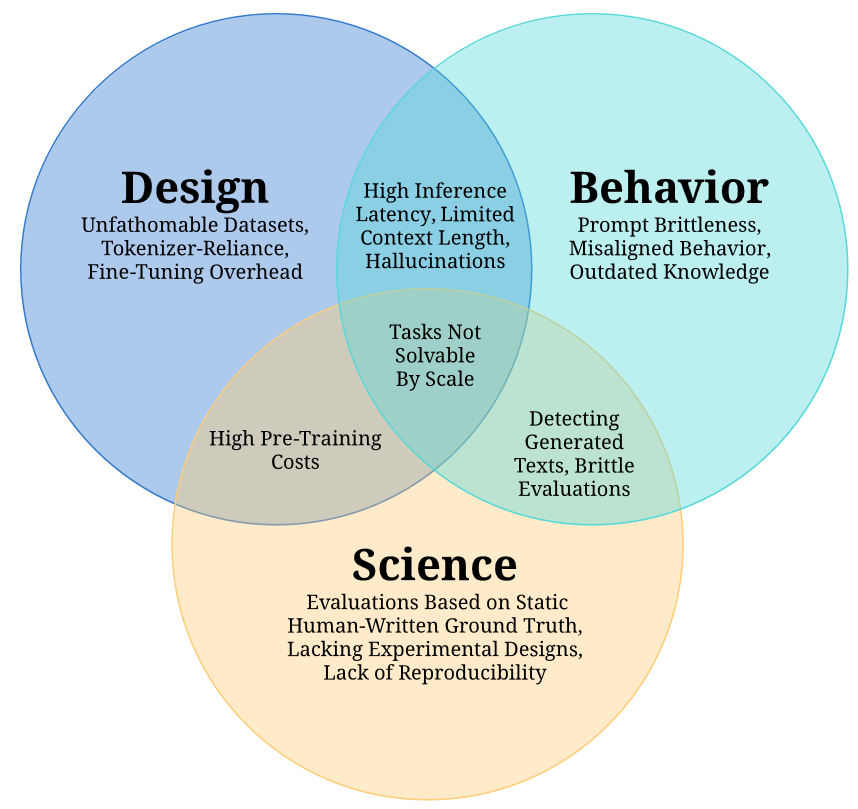
APPENDIX: Full list of challenges of Large Language Models
The survey paper, describes following challenges:
I. Design Challenges
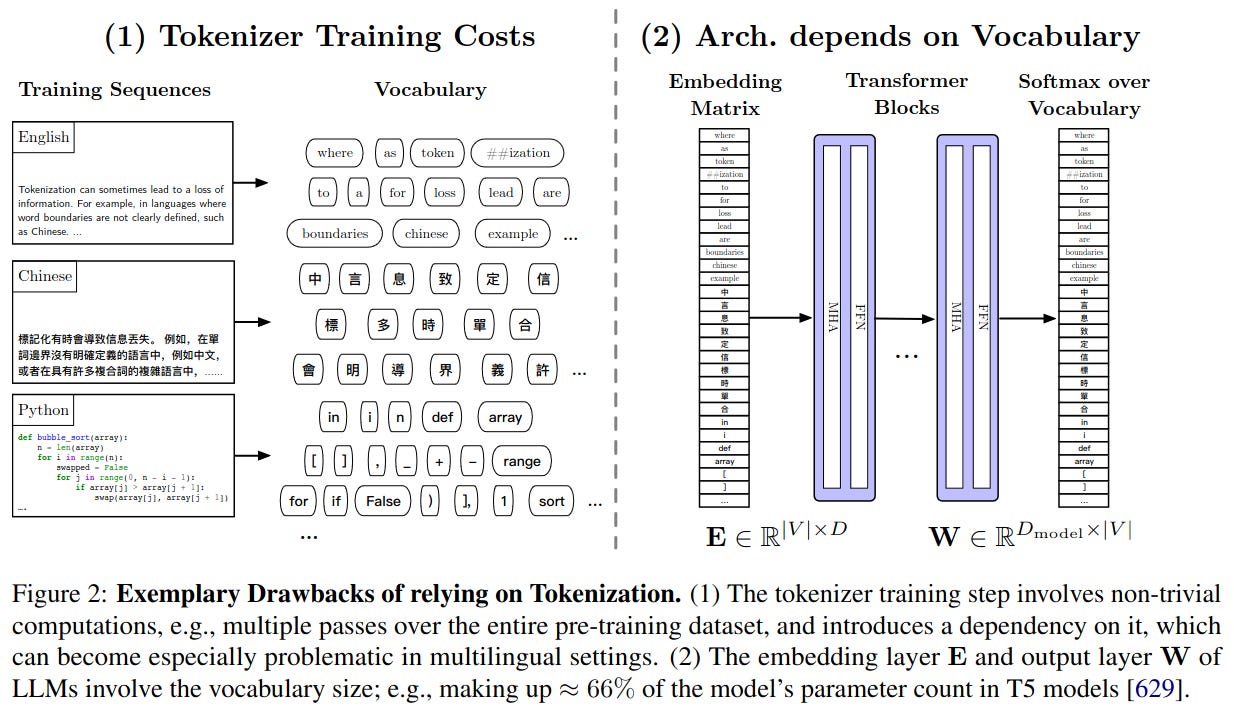
- Unfathomable Datasets: The massive size of training datasets makes comprehensive quality control impractical - Tokenizer-Reliance: Dependence on tokenization introduces computational overhead and other issues - High Pre-Training Costs: Training LLMs requires prohibitive amounts of compute and energy - Fine-Tuning Overhead: Adapting LLMs requires large memory and still full backpropagation
II. Behavioral Challenges
- High Inference Latency: LLMs are slow due to low parallelizability and large memory footprints - Limited Context Length: LLMs struggle with long text inputs beyond training lengths - Prompt Brittleness: Small prompt variations can drastically change model outputs - Hallucinations: LLMs can generate confident but incorrect text - Misaligned Behavior: LLMs often behave in ways misaligned with human preferences - Outdated Knowledge: Pre-trained knowledge can become outdated without retraining
III. Scientific Challenges
- Brittle Evaluations: Minor evaluation changes drastically alter measured capabilities - Reliance on Static Ground Truth: Human-labeled benchmarks become outdated - Indistinguishable Text: Detecting LLM-generated text remains challenging - Tasks Not Solvable by Scale: Some tasks may need algorithms beyond scale - Lacking Experimental Design: Ablations and details often omitted - Lack of Reproducibility: Parallel training and black-box APIs reduce repeatability